In manufacturing, batching work made economic sense. When changing a machine over was expensive, it was cheaper to run large volumes at once. Large batches reduced setup cost and simplified coordination.
That logic does not always hold in knowledge work. When many elements are tied together and delivered as one unit, the number of moving parts increases. More moving parts mean more ways for things to interfere with each other. The number of interfaces and dependencies increases complexity. Testing and integration become more difficult and slower.
Large batches also increase work-in-process (WIP). A large item occupies capacity for a long time. While it sits in the system, other work waits. Little’s Law tells us that as work in process increases, average cycle time increases. When batch size increases, both WIP and variability tend to increase, and delay grows faster than most people expect.
Reducing batch size lowers the amount of work tied up in the system. It shortens feedback loops, limits risk, and makes problems easier to isolate. The rest of this article explains why that happens and how to decompose work into smaller, usable units without creating unnecessary overhead.
Batching Ideas is Useful
Chunking ideas is natural and necessary. We group details into larger concepts to communicate and reason effectively. It is more practical to say “a television” than to describe every component inside it. Abstraction allows us to plan, coordinate, and set goals.
Language itself works this way. We recognize words as whole units rather than processing individual letters one at a time. We think in meaningful groupings.
The problem is not conceptual batching. The problem arises when large conceptual groupings are treated as single delivery units. When an abstract idea is translated into execution without decomposition, complexity accumulates, wait times increase, and risk increases.
Batch Size Examples
A batch is the amount of work grouped together and treated as a single unit of delivery. The larger the batch, the more work is tied together and moved through the system at once.
Examples of large batches of work include:
- Clean the house
- Plan a party
- Build a software application (or a feature with many elements)
Each of these represents a collection of smaller activities that are bundled together and committed as one item.
Clean the house. This appears to be a single task. In reality, it contains multiple distinct activities:
- Clean the downstairs bathroom
- Vacuum the den
- Dust the furniture
- Wash the dishes
- Clean the oven
- Mop the kitchen floor
If “clean the house” is treated as one commitment, none of the individual rooms are considered complete until the entire house is finished. Feedback is delayed and risk accumulates across all areas. The full bundle remains work in process for the entire duration. While it occupies capacity, other work waits. Larger commitments stay in the system longer, increasing overall delay.
Plan a party. Like cleaning a house, this appears to be one commitment. In practice, it includes many separate activities:
- Make a list of invitees
- Select and reserve a location
- Design and print invitations
- Purchase postage
- Address and mail invitations
Several of these steps depend on earlier decisions. The guest list may affect the size of the venue. The venue determines the date. The date affects everything that follows. These are dependency relationships. If these activities and their dependencies are bundled together and treated as one delivery, errors discovered late require rework across multiple steps. Risk compounds as more elements are added to the batch.
Build a software application. This may be treated as one large commitment, but it includes many separate capabilities:
- Create login and password management
- Build account management screens
- Implement settings configuration
- Integrate credit card payment processing
Each capability interacts with others. Login affects account management. Account data flows into payment processing. Security rules apply across all screens.
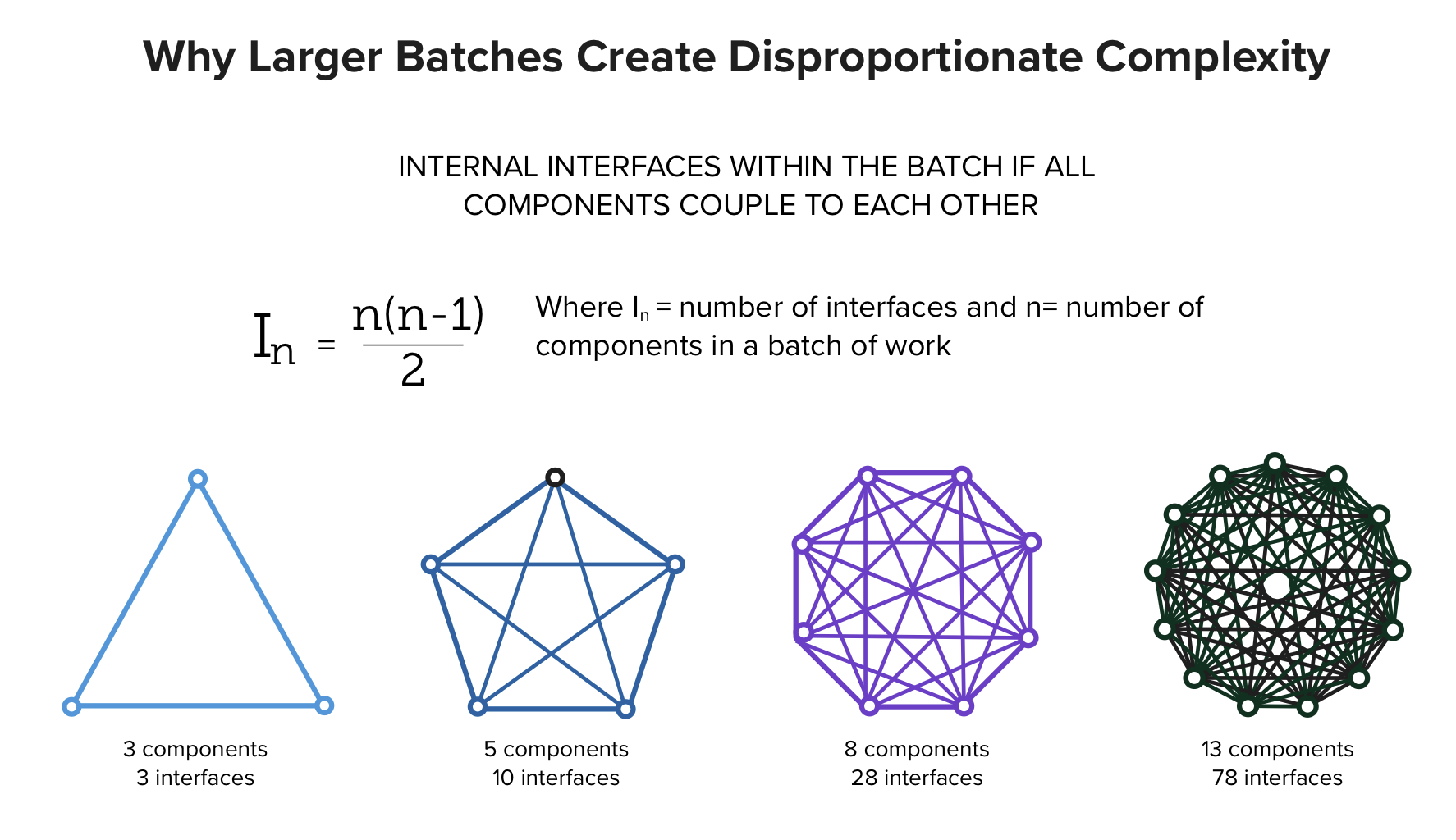
As more capabilities are bundled together, the number of interfaces between them grows rapidly. Even if we consider only the internal components of a batch and the interfaces between them, complexity escalates sharply as the number of components increases. If a system has n components and each can potentially interact with every other, the number of possible pairwise interactions is n(n−1)/2. Adding one more component does not add one new interaction. It adds many. The coordination and testing burden grows faster than the number of features being added.
Under this full internal coupling assumption, the number of interfaces between components within the same batch increases quadratically, as illustrated below:
Business rules multiply as more capabilities are introduced. Workflow paths increase as interactions between capabilities grow. The effective surface area of the system becomes larger. As we begin attempting to model the impacts of coupling with components outside the batch of work, the number of interfaces increases dramatically. When those external components also connect to other systems, interfaces multiply again. When a change in one interface forces changes in other components, the work multiplies again.
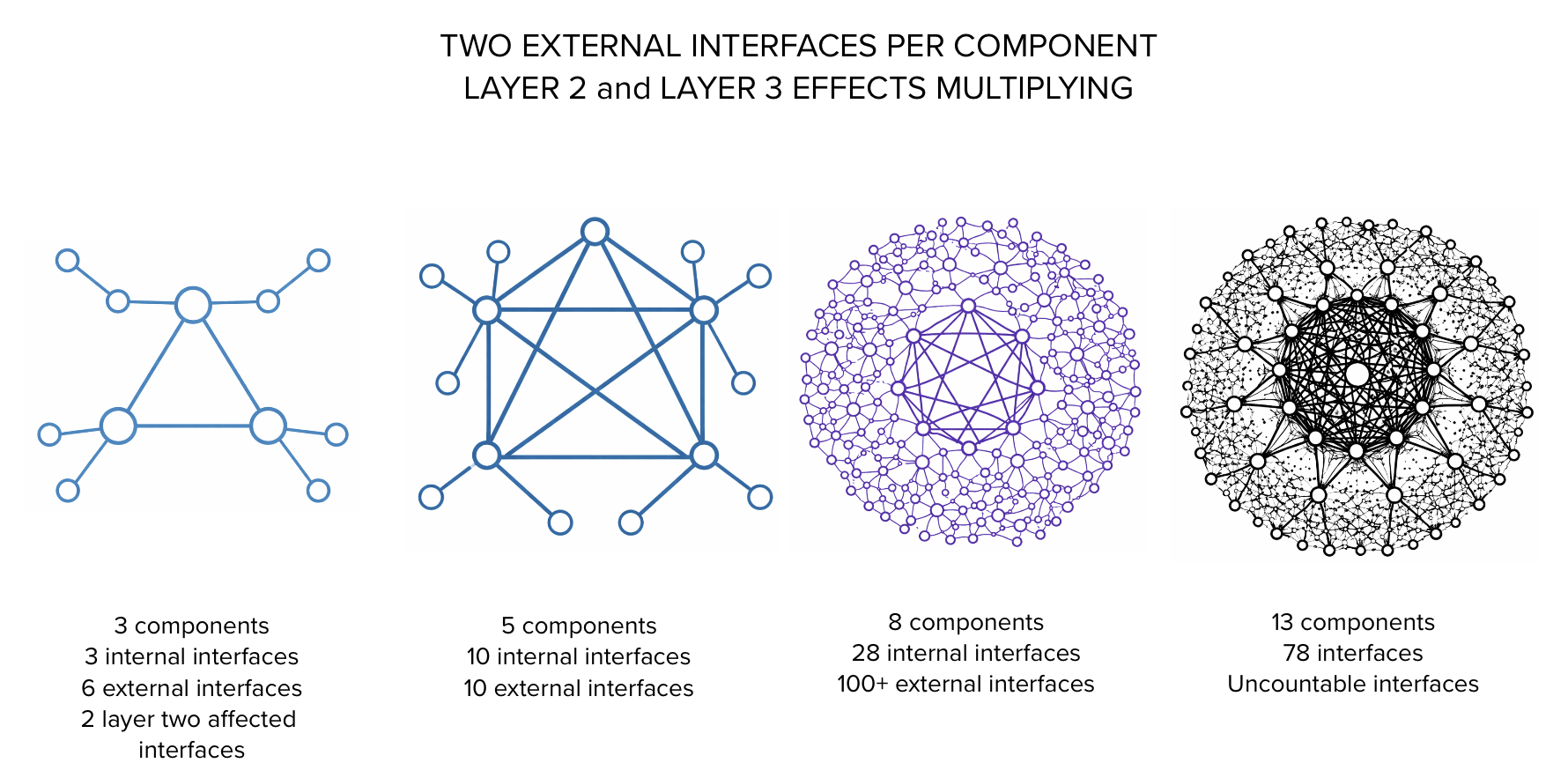
More interfaces mean more code and more rules. The multiplication of complexity as batch size increases is non-linear. This creates more opportunities for defects. When defects appear, they are harder to isolate because multiple capabilities were introduced at the same time. Integration and validation occur later and under greater complexity.
The entire release remains work in process until all components function together. As batch size grows, both complexity and effective WIP grow with it. Delay and rework follow. As shown in the illustration, releasing three components is less risky than releasing thirteen components.
The Cost of Complexity
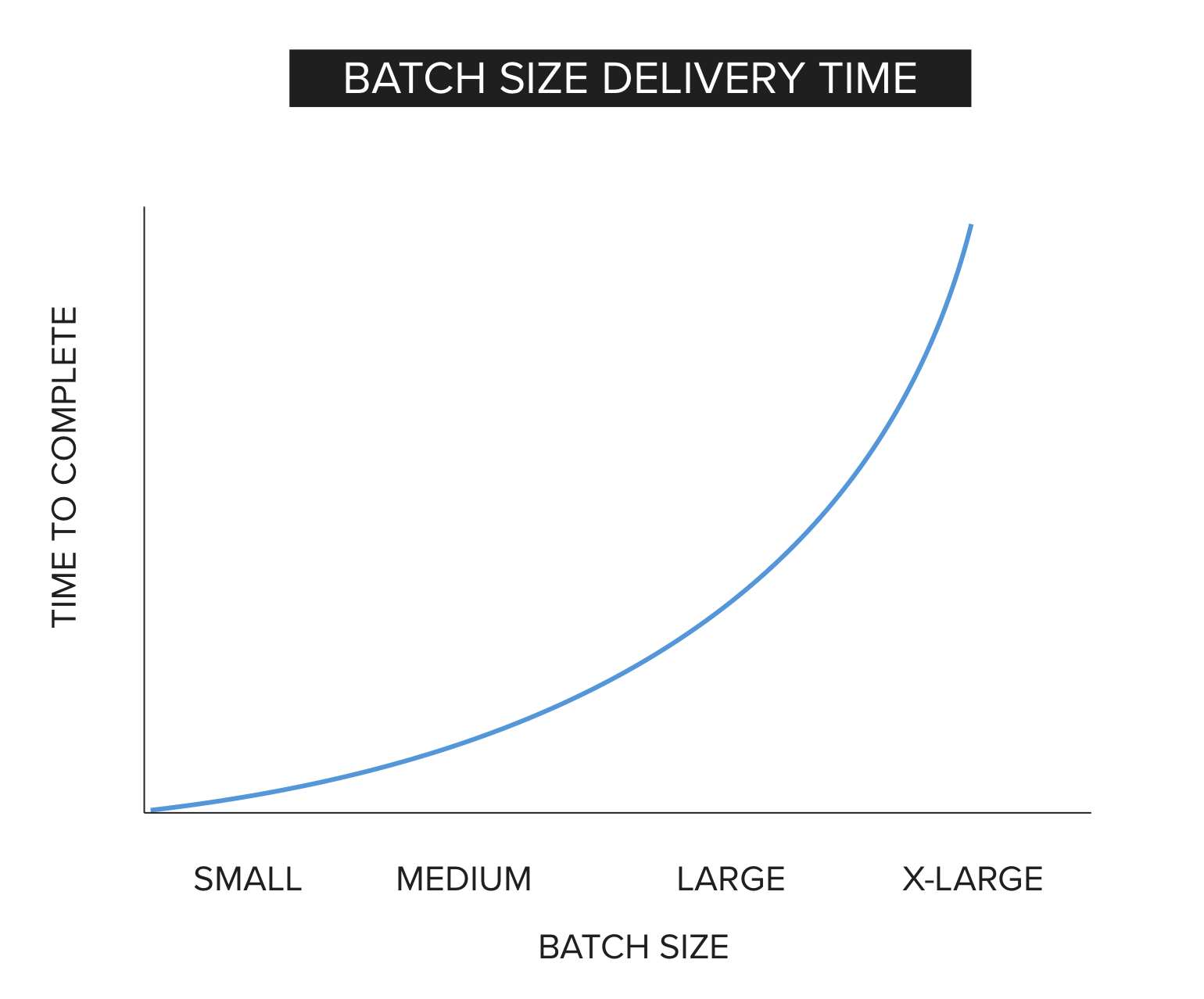
When work is done in large batches, it creates additional difficulty. Reducing the size of work items improves flow.
As more elements are tied together and treated as a single delivery unit, complexity increases. Complexity arises from the number of connections and dependencies between components. If a small change is introduced and tested in isolation, the scope of testing is limited and defects are easier to locate. If many changes are introduced at once, isolating the source of a defect becomes more difficult. Complexity is one of the primary consequences of increasing batch size.
A traditional software development project is typically treated as a single large batch. It has one delivery date, a defined scope, and a single budget. All features are expected to be delivered together. As more features are developed together, interdependence increases, which contributes to integration delays and defects. When the release occurs, debugging and validation must address many interacting changes at once. Larger releases often require coordinated effort across multiple teams to stabilize the system.
The effects of complexity are:
- Coordination overhead. As complexity increases, coordination overhead increases in a non-linear way, requiring more communication, alignment, and validation effort.
- Increased risk. Increased coupling increases the blast radius of defects. A defect in one component is more likely to affect others.
- Increased cycle time. Complex items occupy capacity longer. Large work items are more vulnerable to variability in the form of interruptions and reprioritizations. This increases the cost of switching from one plan to another. Queuing will form around the item as it occupies capacity.
- Delayed learning and reduced adaptability. As we deliver more work less frequently with longer timelines, it is more difficult for a person, team, or organization to learn from the experience when many changes are introduced simultaneously in a large release.
- Rework. As more complex work items are developed, more time is spent revising work as problems are discovered.
These combined effects produce the accelerating curve shown above. Given these effects, how do we decompose work into smaller batches?
Decomposing Work
The objective of decomposing work is to reverse the effects created by large batches:
- Shorter timelines and faster feedback. Feedback should occur as soon as possible on each delivered item, increasing the likelihood that the right thing is built in the right way.
- Reduced risk. Work should be structured so that if it is incorrect or problematic, it can be reversed or corrected with minimal impact.
- Lower coordination overhead. Smaller units of work reduce the number of simultaneous dependencies and limit the need for broad coordination across teams.
For example, a request for an entire mobile app can be decomposed into smaller, usable deliverables organized by workflow. For instance:
- Authenticate
- View account details
- Update account details
If “Authenticate” does not fit into an iteration, break it down further:
- Enter user ID and password and submit
- Validate credentials and show success/failure
- Mask password entry and allow reveal/hide
- Provide “Create account” link when no account exists
- Provide password reset flow
- Add step-up verification after a period of inactivity (optional)
If these still do not fit into an iteration, continue breaking them down into smaller deliverables that a user can receive and test.
Smaller deliverables limit rework. If a large authentication change is built and integrated all at once, defects discovered late can force rework across UI, validation logic, and downstream flows. Smaller slices reduce the amount of work at risk before feedback is received.
For software teams, SPIDR (and my DRIPS variant) provides a structured approach to slicing work into smaller, testable deliverables.
Work Decomposition Rules
Make it usable and therefore valuable. Each smaller item should produce something that can be used, evaluated, or tested. In software, a thin, working slice of a feature is usable. A document describing the future feature is not. “Usable” does not necessarily mean necessarily complete or ready for broad release. It means the work produces a result that can be exercised and validated.
Make it small, but not too small. Smaller batches reduce risk and speed feedback, but extremely tiny slices can create unnecessary overhead. Decompose until the item can be completed and validated quickly, without turning the work into administrative noise.
Insist on customer feedback. Get feedback on finished work from real users or stakeholders. Prefer direct interaction over proxy interpretation. Show smaller deliverables more frequently to shorten the feedback loop.
Science, Empiricism, and Natural Work
In many disciplines, work progresses through small, testable increments. Software development itself typically advances through small changes followed by execution and validation. Introducing a limited change and observing its behavior reduces the scope of debugging. Introducing many changes at once increases the difficulty of isolating defects.
Scientific experimentation follows the same principle. Researchers control variables, test a specific hypothesis, observe results, and adjust based on evidence. Each experiment is designed to isolate cause and effect. When too many variables change simultaneously, interpretation becomes difficult.
Business strategy benefits from the same discipline. Instead of committing to large, fixed-scope initiatives that run for months before validation, organizations can introduce smaller increments of capability and measure the results. Early feedback may confirm direction, suggest adjustments, or indicate that further investment is not justified.
Evidence-Based Management is most effective when work is delivered in small, measurable increments. Smaller batches clarify cause and effect, shorten learning cycles, and reduce the cost of being wrong.
