A picture is worth one thousand words. Below is a visual representation of two kanban systems. The top one in blue is spending their time estimating work and labeling it as small, medium, and large. The bottom board, in green, is used by a team that does not label their work with a size but instead attempts to decompose it into smaller yet still valuable items.
Everything about the two teams' work is identical. They face the same factors of probability of blockage through variability, the same punishment for task switching from a blocked item to a new one. They have the same workers performing at the same skill level in the same way. The WIP limits are the same.
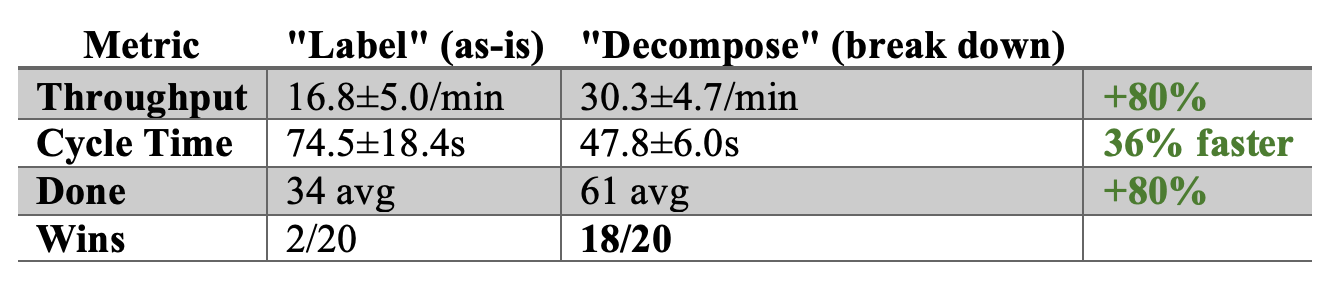
So why is the cycle time on the green board lower?
The items they are working on are smaller. Because these items are smaller:
- Each item is easier to finish
- There are fewer dependencies per item
- Each item has a lower cycle time and is therefore less vulnerable to variability
- There is lower complexity involved with each item
- Less coordination overhead is needed in processing
Smaller batch size equals superior results. Lower cycle times, lower WIP, fewer interruptions, less blockage, and lower coordination costs. Large batches of work tend to hide WIP. WIP is easier to control in a small batch system.
The team using the smaller batches is more maneuverable. They get work done more quickly resulting in potentially faster feedback loops and earlier course corrections. The team saves money by being able to abandon bad ideas more quickly. If interrupted, the work itself is more likely to be completed partially rather than fully scuttled.
I ran the simulation 20 times after completing it. The probability of the team spending their time estimating instead of decomposing work winning was 10%. 90% of the time, the team working in smaller batches will be more productive using their time to break work down rather than arguing about how big it is.
Small batch work is a successful and beneficial work style that has a high probability of being a better value than that of estimation and labeling of work size.
Simulation Details
Definition of Workflow. Seven states: Backlog → Design → Dev → Review → QA → Integrate → Done. Design, Dev, Review, and QA are work-in-process with 5 workers each. Integrate is a single-server (CI/CD pipeline). Backlog is a queue. Work pulled from the backlog is considered started and in-process.
WIP limits. Both boards use WIP=9 per work column. The Integrate and Done column have no limit. Backlog is capped at 20 items.
Work items. 500 items are pre-generated before either board starts. Each item has a random size (33% Small, 33% Medium, 33% Large), a base difficulty drawn from a lognormal distribution (median 1.0, spread 0.67–1.49), and a gamma-distributed inter-arrival time (mean 1.2s, cv²=1.5). Both boards draw from this identical sequence so neither receives easier work.
Item sizes. Small: 1x service time, 1x block rate, 1x integration time, 18px card. Medium: 2x service time, 1.5x block rate, 1.5x integration time, 23px card. Large: 4x service time, 2x block rate, 2.5x integration time, 29px card.
Board A ("Estimation Team"). Items enter the backlog and are pulled into Design as-is. A Large card stays Large through the entire pipeline. Size is a label — acknowledged but not acted on. The team spends pre-work time estimating size and then labeling each work item with that size. Cards are sized to reflect these beliefs. The estimates are treated as 100% correct. Uncertainty is not part of the simulation.
Board B ("Decomposition Team"). Small items pass through the backlog unchanged. Medium and Large items are flagged as "needs refine" and queued for a dedicated refinement worker. That worker decomposes M→2 Small cards and L→3 Small cards. Decomposition takes real time: 3.0 seconds (gamma-distributed) for a Large, 1.5 seconds for a Medium. While an item awaits refinement it sits in the backlog with a ⚙ icon and cannot be pulled into Design. Only one item is refined at a time.
Total work preservation. When a Medium (2× difficulty) is split into 2 Smalls, each Small carries difficulty × 2.0 / 2 = the original difficulty. When a Large (4× difficulty) is split into 3 Smalls, each carries difficulty × 4.0 / 3. The total effort across all pieces equals the original. No work is created or destroyed. This provides a conservative model as in reality downsizing work items often results in reduction of complexity in non-linear ways.
Service time. Each work stage draws from a gamma distribution (cv²=1.5) with a stage-specific mean: Design 1.5s, Dev 2.0s, Review 1.5s, QA 1.5s. The drawn time is multiplied by the card's difficulty (which already incorporates size). A context switch adds a flat 1.5 seconds when a worker picks up a card they weren't just working on. This helps account for the punishing effects of task switching. When a worker changes focus from one item to another, there is cost from putting the previous work on hold and taking up the new work.
Mid-work blocking. Every tick, each active card has a probability of hitting an impediment: min(12%, 0.6% + 0.3% × seconds_in_current_stage) multiplied by the card's size block multiplier (1.0/1.5/2.0 for S/M/L). Larger cards discover more impediments. When blocked, the card sits in its column consuming a WIP slot. Block duration is 3–7 seconds (gamma), mildly scaled by stage age and size. Blocked cards resolve at a fixed rate — no swarming. This provides a conservative representation of variability affecting longer-lived work items. In many advanced teams, workers share work items, and they can help each other unblock work.
Weinberg focus model. Each additional card a worker is mentally tracking (touched in this column but not completed) costs 20% productivity. A worker juggling 3 open items runs at 60% speed. Floor is 20% — workers never stop entirely. This is also generous compared to what is expected in reality.
Standup meeting overhead. Every 15 sim-seconds, each work column recalculates its coordination cost: cards_in_column × 0.6s / 15s = fraction of time lost. At 9 cards: 36% overhead. At 5 cards: 20%. Capped at 50%. This reduces every worker's effective speed in that column.
QA rework. When a card completes QA, there is a 12% × size block multiplier chance it gets sent back to Dev. Large items rework at 24%, Medium at 18%, Small at 12%. The card retains its age and difficulty.
Integration gate. A single server processes cards FIFO from the Integrate queue. Service time: gamma(0.5s) × card difficulty × size integration multiplier × (1 + 2.5% × total system WIP). The service time scales with how many concurrent branches exist in the system. Higher system WIP means more rebasing and merge resolution per integration.
Integration failure. After each integration completes, there is a min(50%, 3% + 0.8% × total system WIP) chance the integration fails. Failed cards return to Dev as rework. At 20 system WIP: ~19% failure. At 36 system WIP: ~32% failure.
Stochastic arrivals. New items arrive to the backlog at gamma-distributed intervals (mean 1.2s, cv²=1.5). If the backlog is full (20 items), the arrival retries after 0.5 seconds.
Pre-computed warmup. 90 seconds of simulation run invisibly before the visual starts. Both boards are fully loaded and flowing before the user sees anything. Measurement begins only after warmup — all displayed metrics are steady-state.
Measurement window. 120 seconds of real-time simulation after warmup. Throughput, cycle time, and WIP are measured only during this window. This warm-up is done before the simulation begins to prevent variation in results from the simulation being unstable at start time.
What the simulation does not model:
- No cross-team dependencies between cards.
- No shared test environments or resources between stages.
- No worker learning, fatigue, or morale effects.
- No batch deploy constraints.
- No product owner or stakeholder feedback loops.
- No cost of delay or opportunity cost.
- Workers cannot move between stages.
- The refinement worker is dedicated — in reality, decomposition might be done by the same developers who build features.
These constraints were put in place to reduce the number of variables involved and because they cannot be realistically modeled.
