Knowing and labeling work item types enables meaningful measurement of flow through the system. When cycle time, WIP, and throughput are measured by type, delivery becomes predictable rather than speculative.
In product development, the following work item types are typically valuable to measure:
- New feature
- Update or improvement to an existing feature
- Defect fix
- Remove a feature
You may find that delivering a new feature has a predictable cycle time, while a defect fix is completed much faster. When cycle time and throughput are measured by work item type, stakeholders gain realistic delivery expectations and teams gain the ability to manage flow intentionally.
Work item types should provide meaningful measurement resolution that allows a team or organization to see how the system actually performs. In practice, most teams identify work item types inconsistently. When classification is inconsistent, measurement becomes distorted, value is lost, and systemic problems remain hidden instead of being addressed.
Work items in tooling should reflect how work actually flows through the system. When they do, transparency increases and decision-making improves.
Design, Coding, and Testing Stories
Some teams create separate design, coding, and testing stories based on phases in a lifecycle. When work is divided this way, end-to-end cycle time becomes invisible because each card represents only a portion of the overall effort. Cards are opened and closed within each phase, and a new card is created for the next phase. As a result, no single item represents the full journey from start to finish.
Teams often adopt this pattern because the end-to-end cycle time appears too long. Functional groups may feel they are being held accountable for delays that occur upstream or downstream from their own work. In siloed organizations, work is handed off between teams, reinforcing the desire to measure only the portion each group controls.
In other cases, separate tools or automated deployment pipelines make it easier to manage work in phases rather than as a single flowing item. These approaches may address local constraints, but they introduce a systemic cost.
When work is divided into phase-based cards, measured cycle time appears artificially short because each item exists only within its functional boundary. The organization loses the ability to see and manage flow across the entire system, which is a far greater cost than the local issues this structure attempts to solve.
In the Kanban example, phase-based work items are represented by different colors. When Analysis is complete, the analysis card is closed. A new design card is opened and later closed. Coding, testing, and release follow the same pattern. Each function tracks its own work, but no single card represents the entire flow of value.
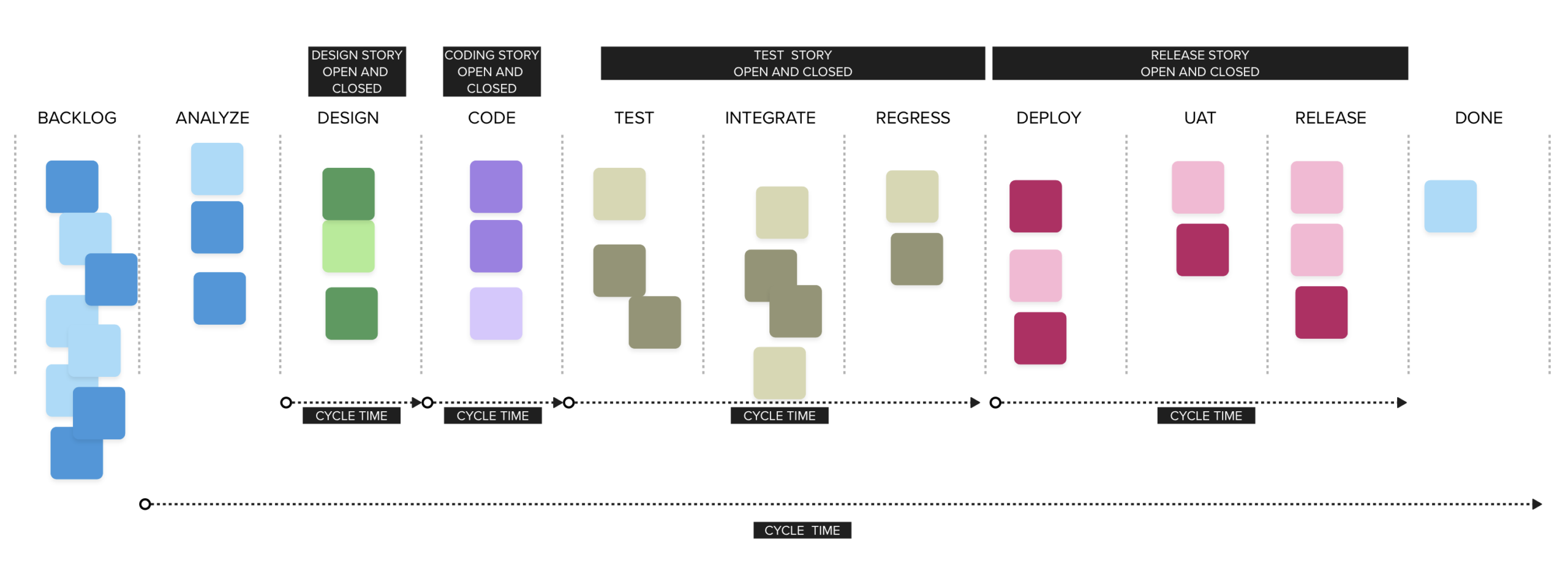
Each functional team working in a silo is using cards to represent their part of the workflow. Consequences of this behavior:
- The queues between phases are invisible. The previous phase’s work item is closed, and the next item has not yet been created. The work is still waiting in the system, but it is no longer visible.
- System-level WIP is hidden. Each phase can see and measure its own WIP, but no one can see the total WIP across the entire system.
- System-level cycle time cannot be calculated. Individual phase cards have measurable cycle times, but the true end-to-end cycle time of the work remains unknown.
To create transparency around WIP and system-level cycle time, a work item must represent the deliverable from the first meaningful step through completion. A single item should enter the system and remain visible until the work is finished.
When end-to-end cycle time is invisible, any forecast based on our cycle time data is unreliable, because we are measuring fragments of work rather than the flow of value.
In software development, this typically means one work item represents an idea from commitment through release to a customer. Organizations may choose broader or narrower system boundaries depending on what they need to measure. What matters is that the item reflects the true flow of value so that queues and WIP become visible and manageable.
Never divide work items by phase. Create one card that represents the full unit of value and keep it alive until delivery.
Without end-to-end visibility, forecasting becomes guesswork.
Technical Stories
Every backlog item, even the most technical, exists for a business reason and has user or organizational impact. Yet many teams divide work into “business stories” owned by product and “technical stories” owned by engineering.
In some organizations, this split emerges from an attempt to ensure capacity is allocated to technical debt and platform work. While the intent is reasonable, the structural consequences are significant.
When Product Owners are measured primarily on feature delivery, they naturally prioritize visible feature work over technical sustainability. As a result, engineering organizations often respond by reserving a percentage of capacity for technical work to protect long-term stability. This arrangement attempts to correct a governance problem through structural division.
Over time, developers begin managing a separate stream of work and prioritizing it alongside the Product Owner. This creates parallel decision-making and obscures value. Technical stories are completed, but their business impact is often unclear. Flow metrics become distorted because the system no longer reflects a single ordered stream of value.
The durable solution is not to divide the backlog, but to develop Product Owners who are accountable for the full economic performance of the product. That includes removing unused features, addressing technical debt, and investing in platform capability. Achieving this requires aligning incentives so that product leadership is measured on long-term value, not short-term feature output.
A deeper issue emerges when capacity is divided by category. How do you maintain a single ordered backlog when a fixed percentage must be allocated to a particular type of work? Are all items prioritized together? If estimates are wrong, how does the organization adapt when value discovery depends on work sitting in two separate queues that are both treated as equally important?
In the following illustration, there are two backlogs – one for tech work and the other for feature work. There are problems with this arrangement.

- When two queues exist, it is no longer clear which item is most important. Guardrails for constraining WIP weaken because priorities compete rather than align. Teams either pull too much work into progress or spend excessive time negotiating sequencing. When product leadership and engineering leadership disagree, prioritization pressure shifts to the team, where resolution is slow and often political.
- In this model, the Product Owner never fully owns the product. Lessons about managing technical debt and balancing long-term capability against short-term output are deferred rather than learned.
All work competes for the same scarce capacity and should be ordered together. The Product Owner’s role is to maintain a single prioritized backlog so that WIP can be constrained and flow optimized. When work exists in two separate priority structures, order degrades, WIP expands, and flow slows.
When WIP cannot be constrained against a single ordered backlog, lead time variability increases, and our throughput data loses its ability to predict delivery.
Dividing the backlog into technical and business categories and allocating capacity by percentage masks governance problems rather than solving them. It delays learning, distorts flow, and weakens accountability.
When priority is divided, lead time stability collapses.
Creating Valuable Work Items That Are Small
Creating small, valuable work items is difficult for teams new to Lean ways of working. When backlogs feel unstable or unclear, developers often respond by requesting more detailed specifications from the Product Owner, sometimes asking them to define the solution rather than the problem. This increases batch size, reduces team ownership, and slows learning. In low-trust environments, the team may interpret this behavior as protection from accountability rather than a constraint on flow.
For a Product Owner accustomed to writing formal business requirements, it may feel irresponsible to create a backlog item with minimal specification. An outcome-oriented request such as, “Improve performance so that more users complete this workflow,” can seem insufficient. Yet this is a valid unit of value. It defines intent without prescribing the solution, allowing the team to explore, decompose, and deliver incrementally.
That outcome can be broken into smaller valuable increments, such as:
- Improve performance of a specific component within the workflow
- Optimize a single step in the process
- Improve performance for one user segment or usage scenario
- Improve one path through the workflow before expanding further
Each of these remains outcome-focused while reducing batch size. Smaller batches reduce the amount of work in process, shorten feedback loops, and stabilize cycle time, which directly improves delivery predictability.
If teams want to decompose work into smaller batches while still delivering meaningful value, they must deliberately develop the skill of outcome-based decomposition. One structured approach is SPIDR, which I refer to as DRIPS to emphasize that the spike is a last resort. Developing this capability is a cultural shift. It enables small-batch flow, reduces upstream bottlenecks, and supports empirical hypothesis testing rather than large speculative commitments.
Don’t Cover Up Your Problems
A recurring mistake in adopting Lean and agile practices is reshaping them to fit the existing system rather than allowing them to expose its weaknesses. Phase-based cards, split backlogs, and percentage-based capacity allocations are examples of this pattern. They preserve familiar structures while concealing systemic delays and governance problems.
These practices were not intended to accommodate the status quo. They were designed to reveal constraints so they can be addressed. When techniques are bent to avoid discomfort, the organization retains its existing inefficiencies and forfeits the return on its investment in change.
Do not redesign your metrics to protect your structure. Redesign your structure to improve flow.
The methods are not meant to conform to the way things work today. The organization is meant to evolve.

Last updated 2026-02-25